Boost库的assign可以帮助我们把一系列的值赋给容器,并且语法更加清晰和简洁。下面我主要以vector和map容器为例,介绍assign中比较常用的赋值方法。其他容器的赋值方法与此类似,故不再赘述。
1. 使用重载操作符+=
vector<int> vctTemp;
vctTemp += 1, 2, 3;
// 打印出1,2,3
copy(vctTemp.begin(), vctTemp.end(), ostream_iterator<int>(cout, " "));
2. 使用push_back
push_back(vctTemp)(4)(5)(6); 或者
push_back(vctTemp) = 4, 5, 6;
另外,如果某容器有push_front函数,也可以使用assign中对应的push_front。
3. 使用list_of
vector<int> vct2 = list_of(7)(8) (9); 或者
vector<int> vct2 = list_of(7)(8) (9) .to_container(vct2);
array<int, 3> ay = list_of(1)(2)(3); 或者
array<int, 3> ay = list_of(1)(2)(3) .to_array(ay);
stack<int> sk = list_of(1)(2)(3).to_adapter(sk);
注意:用list_of给容器适配器赋值时,必须使用to_adapter,否则无法编译通过。
4. 使用tuple_list_of
vector<tuple<int, string, int> > vctTuple = tuple_list_of(1, "hi", 2)(3, "hu", 4);
BOOST_ASSERT(get<1>(vctTuple[1]) == "hu");
5. 使用repeat
push_back(vctTemp)(7)(8)(9).repeat(3, 10);
其中repeat函数的第1个参数为重复的次数,第2个参数为参数的值。
6. 使用range
push_back(vctTemp)(7)(8)(9).range(vct2.begin(), vct2.begin()+2);
其中range(iterBegin, iterEnd)函数使用的数值范围为[iterBegin, iterEnd)。
7. 使用insert
map<int, string> mapTemp;
insert(mapTemp)(1, "Hello")(2, "world")(3, "crearo");
8. 使用map_list_of(只能用于map容器)
map<string, int> map2 = map_list_of("hefei", 1)("nanjing", 2)("wuhan", 3);
2009年3月31日星期二
2009年3月30日星期一
【原】设计3+2之认识粒子
3D中有着很炫很吸引人的一项功能就是粒子系统,它在模仿自然现象、物理现象及空间扭曲上具备得天独厚的优势。(烟云、火花、爆炸、暴风雪或者瀑布、雨、雪、流水和灰尘等)随着功能的逐步完善,粒子系统几乎可以模拟任何富于联想的三维效果,同时为了增加物理现象的真实性,结合了空间扭曲能对粒子流造成引力、阻挡、风力等仿真影响。使其更加震撼我们的眼球。目前,粒子系统技术被广泛用于电影、电视及大型3D游戏地制作。还记得《蜘蛛侠3》中的可以随意变换并操控沙子的沙人吗,《指环王》里大型的战争场面,《最终幻想》中美幻的空间场景吗....

2009年3月29日星期日
【原】ArcGIS中最短路径的实现(二)
上次介绍了用几何网络实现的“最短路径”,姑且这么叫吧。这次我们用网络数据集实现真正的最短路径功能,跟上次一样,我们先准备数据。
- 先打开ArcCatalog,连接到目标文件夹,假定该文件下有一个名为road的道路图层。
- 在road图层上右键新建一个网络数据集,并按照其默认设置直至完成。
- 打开该地图的工作空间,把刚才新建的网络数据集添加工作空间中。
- 在网络分析菜单中选择新建最近设施点。
这时在工作空间里,可以看到多了一个名为“Closest Facility”的图层。它下面还有4个子图层,名字分别为“Facilities”,“Incidents”,“Barriers”,“Routes”。“Facilities”就是设施点图层,也就是目的点,“Incidents”的意思就是出发点,“Barriers”是障碍点,意思就是地图某条道路附近有一个障碍点,如果障碍点与道路距离在容限范围内,则表示此道路不通,“Routes”就是最终的结果。这样我们编程实现最短路径的思路就出现了:
- 添加出发点。
- 添加目的点。
- 生成最优路径,获取结果。
这里的添加出发点或者目的点,是往“Facilities”或“Incidents”图层上添加元素。获取结果也是从“Routes”中获取Polyline。往“Facilities”或“Incidents”图层上添加元素用到的主要方法是INALocator的QueryLocationByPoint函数,生成路径主要接口是INASolver和它的Solve方法。获取结果是按属性查找,因为“Routes”类其实就是一个图层类,只不过只是存在于内存,这个查找方法网上很多。
相关链接:ArcGIS中最短路径的实现(一)
【原】Boost库之timer的使用
我们在编程中有时需要计算运行某一段代码所花费的时间,通常的方法是通过计算该段代码首尾的GetTickCount的差值来获得。这种方法虽然可取,但需要调用两次GetTickCount函数,总让人觉得有些繁琐。Boost库的timer提供了对计时特性的封装,简化了代码的编写,并且它具有跨平台的优点。
Boost库的timer主要封装了timer、progress_timer和progress_display这3个计时类,使用起来非常简单,下面逐一介绍。
timer类的构造函数会在内部获得一个起始时间并开始计时,其elapsed成员函数会计算所消耗的时间,其restart函数重新开始计时。示例代码如下:
timer tx;
Sleep(1000);
cout << tx.elapsed() << endl;
progress_timer类是对timer类的进一步封装,使用起来更加方便,它会在析构函数中自动打印出所消耗的时间。示例代码如下:
{
progress_timer pro;
Sleep(1000);
}
progress_display类以图形化的方式给出了当前所花费的时间刻度占总时间刻度的比例。其构造函数为:
explicit progress_display(unsigned long expected_count, std::ostream &os = std::cout, conststd::string&s1="\n", const std::string & s2 = "", const std::string & s3 = "" );
其restart函数用于重新开始计时,count函数用于获得当前所花费的时间刻度,expected_count函数用于获得总的时间刻度。另外,progress_display类还重载了+=和前缀++操作符,用于增加当前的时间刻度值。示例代码如下:
progress_display pd(15, cout, "hello:\t", "hujian:\t", "Start:\t");
for (int i = 0; i < 15; i++)
{
Sleep(100);
++pd;
}
这3个类的实现比较短,均在timer.hpp和progress.hpp头文件中,大家有空可以阅读一下源代码,以加深对这3个类的理解。
Boost库的timer主要封装了timer、progress_timer和progress_display这3个计时类,使用起来非常简单,下面逐一介绍。
timer类的构造函数会在内部获得一个起始时间并开始计时,其elapsed成员函数会计算所消耗的时间,其restart函数重新开始计时。示例代码如下:
timer tx;
Sleep(1000);
cout << tx.elapsed() << endl;
progress_timer类是对timer类的进一步封装,使用起来更加方便,它会在析构函数中自动打印出所消耗的时间。示例代码如下:
{
progress_timer pro;
Sleep(1000);
}
progress_display类以图形化的方式给出了当前所花费的时间刻度占总时间刻度的比例。其构造函数为:
explicit progress_display(unsigned long expected_count, std::ostream &os = std::cout, conststd::string&s1="\n", const std::string & s2 = "", const std::string & s3 = "" );
其restart函数用于重新开始计时,count函数用于获得当前所花费的时间刻度,expected_count函数用于获得总的时间刻度。另外,progress_display类还重载了+=和前缀++操作符,用于增加当前的时间刻度值。示例代码如下:
progress_display pd(15, cout, "hello:\t", "hujian:\t", "Start:\t");
for (int i = 0; i < 15; i++)
{
Sleep(100);
++pd;
}
这3个类的实现比较短,均在timer.hpp和progress.hpp头文件中,大家有空可以阅读一下源代码,以加深对这3个类的理解。
2009年3月26日星期四
【原】关于Visual Assist X(VC助手)几个最新版本的比较与破解下载——更新到10.5.1715.0
下面归纳下VA近期几个版本的问题:
1557:对宏的支持不好,经常无法提示;跟以前的所有版本一样,注释超过一定行数就被“...”代替了,郁闷。
1561:比以前版本最大的改进就是注释能够显示完全,超爽;对宏的支持也好多了,但是在有些情况下宏的提示还是有问题,并且goto不到源代码。
1626和1640:VA工具栏耳目一新;增加了一些更加人性化的配置选项;但先天有一个超级大Bug,AutoText在系统是中文用户名的情况下不会自动提示(这个问题VA提供了一个变通的解决办法,参照相关文章1),而且听说在有些用户的环境下对中文的支持很不好(我用的时候没有发现问题)。后来又发现一个问题是当VC工程打开一天或者更久后,所有建议和颜色都会失效,不过这个ms是由于破解不彻底导致的。
1649:修复了1626和1640的一些重要Bug, 包括上文提到的系统中文名下AutoText失效和对中文支持不好的问题,并且开始了对VS2008的支持。但是我只试用了几分钟就又遇到了两个很让人郁闷的问题。第一个是注释格式错乱:(图1:1561的注释 vs 图2:1649的注释 )
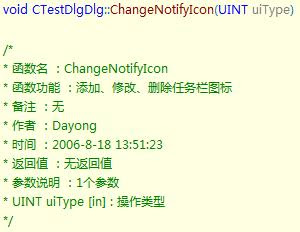
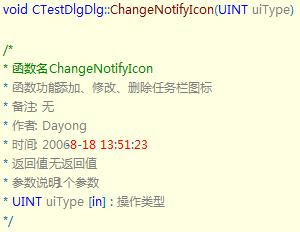
第二个是高亮关键字这个过程效率很低,我在新打开一个文件的时候都是先看到字是黑色的,然后才变成蓝色或其他对应的颜色,这个过程看的一清二楚,让人非常不爽。
1711:这个版本是目前最新的(其实最新的已经到1715了,但据说1715的破解版不是很稳定,所以还是用回1711),但是1649的那两个问题依然存在。
所以对比之下我总结出的结论就是,如果不用VS2008,那么就选择1561,问题算是最少了,对于VA的最新版本,可以尝试一下,一定会有全新的感受,不过新鲜劲儿过了可能就只剩下失望了,让你不得不换回以前的老版本^_^;如果用VS2008,那么只能选择最新的1711。不过我们还是继续期待着tomato能够尽快推出更加稳定、性能更好、更适合中文用户的新版本。
Visual Assist X 破解版本下载地址:1561 1711
关于1649版本Bug的官方解答:http://www.wholetomato.com/forum/topic.asp?TOPIC_ID=8244
关于1640版本Bug的官方解答:http://www.wholetomato.com/forum/topic.asp?TOPIC_ID=7965
关于1626版本Bug的官方解答:http://www.wholetomato.com/forum/topic.asp?TOPIC_ID=7948
1557:对宏的支持不好,经常无法提示;跟以前的所有版本一样,注释超过一定行数就被“...”代替了,郁闷。
1561:比以前版本最大的改进就是注释能够显示完全,超爽;对宏的支持也好多了,但是在有些情况下宏的提示还是有问题,并且goto不到源代码。
1626和1640:VA工具栏耳目一新;增加了一些更加人性化的配置选项;但先天有一个超级大Bug,AutoText在系统是中文用户名的情况下不会自动提示(这个问题VA提供了一个变通的解决办法,参照相关文章1),而且听说在有些用户的环境下对中文的支持很不好(我用的时候没有发现问题)。后来又发现一个问题是当VC工程打开一天或者更久后,所有建议和颜色都会失效,不过这个ms是由于破解不彻底导致的。
1649:修复了1626和1640的一些重要Bug, 包括上文提到的系统中文名下AutoText失效和对中文支持不好的问题,并且开始了对VS2008的支持。但是我只试用了几分钟就又遇到了两个很让人郁闷的问题。第一个是注释格式错乱:(图1:1561的注释 vs 图2:1649的注释 )
第二个是高亮关键字这个过程效率很低,我在新打开一个文件的时候都是先看到字是黑色的,然后才变成蓝色或其他对应的颜色,这个过程看的一清二楚,让人非常不爽。
1711:这个版本是目前最新的(其实最新的已经到1715了,但据说1715的破解版不是很稳定,所以还是用回1711),但是1649的那两个问题依然存在。
所以对比之下我总结出的结论就是,如果不用VS2008,那么就选择1561,问题算是最少了,对于VA的最新版本,可以尝试一下,一定会有全新的感受,不过新鲜劲儿过了可能就只剩下失望了,让你不得不换回以前的老版本^_^;如果用VS2008,那么只能选择最新的1711。不过我们还是继续期待着tomato能够尽快推出更加稳定、性能更好、更适合中文用户的新版本。
Visual Assist X 破解版本下载地址:1561 1711
关于1649版本Bug的官方解答:http://www.wholetomato.com/forum/topic.asp?TOPIC_ID=8244
关于1640版本Bug的官方解答:http://www.wholetomato.com/forum/topic.asp?TOPIC_ID=7965
关于1626版本Bug的官方解答:http://www.wholetomato.com/forum/topic.asp?TOPIC_ID=7948
【原】Boost库之format的使用
Boost库的format提供了类似于C标准库函数printf的格式化字符串功能,并且它是强类型安全的。由于format重载了%操作符,因此,通过单次或多次调用%操作符可以非常方便地格式化字符串。
format的基本语法结构为:format(需要格式化的字符串 ) %参数1 %参数2 …%参数n。下面介绍format的几种使用方法。
1. 直接使用format
cout << format("%2% and %1% and %2%")%16 %"hello" << endl;
其中%1%表示第一个参数,%2%表示第二个参数,其他依此类推。另外,参数是可以复用的。
2. 使用format的str函数
format fmt("%2% and %1%")%16 %"hello";
string s = fmt.str();
cout << s << endl;
3. 使用全局的str函数
format fmt("%2% and %1%")%16 %"hello";
string s = str(fmt) ;
cout << s << endl;
4. 多次调用%操作符
format fmt("%2% and %1%");
fmt %16;
fmt %"hello";
cout << fmt << endl;
5.使用printf风格
cout << format("%d and %s")%16 %"hello" << endl;
6. 使用混合风格
cout << format("%2$s and %1$d")%16 %"hello" << endl;
其中%后面是参数的序号,$后面是printf风格的格式符。
另外,format还提供了一些其他的格式说明符。比如:%nt用于产生一个固定在第n列的\t;%nTx可以将x作为填充字符以代替当前流的填充字符(默认是一个空格)。当实际传入的参数个数与格式化字符串中需要的参数个数不一致时,format会抛出异常。举例如下:
cout << format("[abc%10t]") << format("[%10T*]") << endl;
try
{
cout << format("%1% and %2%") %16 << endl;
}
catch (exception &e)
{
cout << e.what() << endl;
}
最后谈一下使用format时需要注意的两点。一是使用默认的format风格(如%1%)输出浮点数类型时,只是将浮点数转换为对应的字符串,无法保证精度,如果需要保证精度,可以使用printf风格(如%f)输出浮点数类型;二是format不支持直接使用CString作为参数,需要先将CString转换为字符指针(如format("%1% ") %(LPCTSTR)szText)。
format的基本语法结构为:format(需要格式化的字符串 ) %参数1 %参数2 …%参数n。下面介绍format的几种使用方法。
1. 直接使用format
cout << format("%2% and %1% and %2%")%16 %"hello" << endl;
其中%1%表示第一个参数,%2%表示第二个参数,其他依此类推。另外,参数是可以复用的。
2. 使用format的str函数
format fmt("%2% and %1%")%16 %"hello";
string s = fmt.str();
cout << s << endl;
3. 使用全局的str函数
format fmt("%2% and %1%")%16 %"hello";
string s = str(fmt) ;
cout << s << endl;
4. 多次调用%操作符
format fmt("%2% and %1%");
fmt %16;
fmt %"hello";
cout << fmt << endl;
5.使用printf风格
cout << format("%d and %s")%16 %"hello" << endl;
6. 使用混合风格
cout << format("%2$s and %1$d")%16 %"hello" << endl;
其中%后面是参数的序号,$后面是printf风格的格式符。
另外,format还提供了一些其他的格式说明符。比如:%nt用于产生一个固定在第n列的\t;%nTx可以将x作为填充字符以代替当前流的填充字符(默认是一个空格)。当实际传入的参数个数与格式化字符串中需要的参数个数不一致时,format会抛出异常。举例如下:
cout << format("[abc%10t]") << format("[%10T*]") << endl;
try
{
cout << format("%1% and %2%") %16 << endl;
}
catch (exception &e)
{
cout << e.what() << endl;
}
最后谈一下使用format时需要注意的两点。一是使用默认的format风格(如%1%)输出浮点数类型时,只是将浮点数转换为对应的字符串,无法保证精度,如果需要保证精度,可以使用printf风格(如%f)输出浮点数类型;二是format不支持直接使用CString作为参数,需要先将CString转换为字符指针(如format("%1% ") %(LPCTSTR)szText)。
2009年3月21日星期六
【原】Boost库之tokenizer的使用
在tokenizer出现之前,如果我们要对一个字符串进行分割,可能要自己封装一个函数。如果有n种不同的分割规则,那么你要封装n个不同的分割函数……太麻烦了!现在好了,Boost库的tokenizer封装了统一的语法来分割字符串,并且提供了三种常用的分割方式,足以满足我们的绝大多数编程需求。
tokenizer主要由分割器和迭代器两部分组成。分割器用于指定字符串的分割规则,如果不指定任何分割器,则tokenizer默认将字符串以空格和标点(键盘上除26个字母(包括大小写)和数字外的其他可打印字符)为边界进行分割。迭代器用于保存字符串分割后的结果。下面着重介绍tokenizer的三种分割器。
■ char_separator是默认的分隔器,它以一组特定的字符来分隔字符串,其构造函数为:
explicit char_separator(); (默认构造函数)
explicit char_separator(const Char* dropped_delims, const Char* kept_delims = "", empty_token_policy empty_tokens = drop_empty_tokens);
其参数的详细说明如下:
◆ dropped_delims和kept_delims:是两个字符数组,这两个数组中的每个字符都是一个分割符。不同的是,dropped_delims中的分割符本身被丢弃,而kept_delims中的分割符本身作为一个单独的记号被保留在迭代器中。默认构造函数的dropped_delims为空格符,kept_delims为标点符号。
◆ empty_tokens:是否保留长度0的记号。它有两个可选值,keep_empty_tokens表示要保留空记号,而默认的drop_empty_tokens表示丢弃空记号。默认构造函数的empty_tokens为drop_empty_tokens。
■ offset_separator主要用于解析长度和格式都固定的字符串,如身份证或电话号码等。其构造函数为:
template<typename Iter> offset_separator(Iter begin,Iter end,bool bwrapoffsets = true, bool breturnpartiallast = true);
其参数的详细说明如下:
◆ begin和end:指向一个整数容器开始和末尾的迭代器,其中每个元素表示要分割的字段的字符数。
◆ bwrapoffsets: 如果字符串长度大于整数容器中所有字段长度的和,是否重复解析字符串。
◆ breturnpartiallast: 当字符串解析到末尾剩余部分的长度(注意:包括结尾的空字符)小于字段长度时,是保留还是丢弃剩余部分。
■ escaped_list_separator主要用于解析包含转义符、分隔符和引号的字符串。其构造函数为:
explicit escaped_list_separator(Char e = '\\', Char c = ',',Char q = '\"');
explicit escaped_list_separator(string_type e, string_type c, string_type q);
其参数的详细说明如下:
◆ e:为单个转义符或包含多个转义符的串。转义符后跟引号表示引号,转义符后跟n表示换行,连续两个转义符表示作为普通字符的转义符本身。
◆ c:为单个分割符或包含多个分割符的串,字符串以该分隔符为边界进行分割。
◆ q:为单个引号或包含多个引号的串,两个引号中间出现的分隔符不再作为分割标志,而是作为普通字符处理。
最后给出一组简单的测试题,大家既可以借此看看tokenizer的语法,也可以根据回答结果来考察一下你对tokenizer的用法有没有理解透彻。稍后我会在评论中给出正确答案。
a) string s = "hello, crearo-sw blog";
tokenizer<> tok(s);
for (tokenizer<>::iterator beg=tok.begin(); beg!=tok.end(); ++beg)
{
cout << *beg <<endl;
}
b) string str = ";!!;miaocl|zhangwh ||-hujian--terry|";
typedef tokenizer<char_separator<char> > tokenizers;
char_separator<char> sep("-;", "|", keep_empty_tokens);
tokenizers tokens(str, sep);
for (tokenizers::iterator tok_iter = tokens.begin(); tok_iter != tokens.end(); ++tok_iter)
{
cout << "<" << *tok_iter << "> ";
}
c) string s = "20090321";
int offsets[] = {4,2,3};
offset_separator f(offsets, offsets+3, true, false);
tokenizer<offset_separator> tok(s,f);
for(tokenizer<offset_separator>::iterator beg=tok.begin();
beg!=tok.end(); ++beg)
{
cout << *beg << endl;
}
tokenizer主要由分割器和迭代器两部分组成。分割器用于指定字符串的分割规则,如果不指定任何分割器,则tokenizer默认将字符串以空格和标点(键盘上除26个字母(包括大小写)和数字外的其他可打印字符)为边界进行分割。迭代器用于保存字符串分割后的结果。下面着重介绍tokenizer的三种分割器。
■ char_separator是默认的分隔器,它以一组特定的字符来分隔字符串,其构造函数为:
explicit char_separator(); (默认构造函数)
explicit char_separator(const Char* dropped_delims, const Char* kept_delims = "", empty_token_policy empty_tokens = drop_empty_tokens);
其参数的详细说明如下:
◆ dropped_delims和kept_delims:是两个字符数组,这两个数组中的每个字符都是一个分割符。不同的是,dropped_delims中的分割符本身被丢弃,而kept_delims中的分割符本身作为一个单独的记号被保留在迭代器中。默认构造函数的dropped_delims为空格符,kept_delims为标点符号。
◆ empty_tokens:是否保留长度0的记号。它有两个可选值,keep_empty_tokens表示要保留空记号,而默认的drop_empty_tokens表示丢弃空记号。默认构造函数的empty_tokens为drop_empty_tokens。
■ offset_separator主要用于解析长度和格式都固定的字符串,如身份证或电话号码等。其构造函数为:
template<typename Iter> offset_separator(Iter begin,Iter end,bool bwrapoffsets = true, bool breturnpartiallast = true);
其参数的详细说明如下:
◆ begin和end:指向一个整数容器开始和末尾的迭代器,其中每个元素表示要分割的字段的字符数。
◆ bwrapoffsets: 如果字符串长度大于整数容器中所有字段长度的和,是否重复解析字符串。
◆ breturnpartiallast: 当字符串解析到末尾剩余部分的长度(注意:包括结尾的空字符)小于字段长度时,是保留还是丢弃剩余部分。
■ escaped_list_separator主要用于解析包含转义符、分隔符和引号的字符串。其构造函数为:
explicit escaped_list_separator(Char e = '\\', Char c = ',',Char q = '\"');
explicit escaped_list_separator(string_type e, string_type c, string_type q);
其参数的详细说明如下:
◆ e:为单个转义符或包含多个转义符的串。转义符后跟引号表示引号,转义符后跟n表示换行,连续两个转义符表示作为普通字符的转义符本身。
◆ c:为单个分割符或包含多个分割符的串,字符串以该分隔符为边界进行分割。
◆ q:为单个引号或包含多个引号的串,两个引号中间出现的分隔符不再作为分割标志,而是作为普通字符处理。
最后给出一组简单的测试题,大家既可以借此看看tokenizer的语法,也可以根据回答结果来考察一下你对tokenizer的用法有没有理解透彻。稍后我会在评论中给出正确答案。
a) string s = "hello, crearo-sw blog";
tokenizer<> tok(s);
for (tokenizer<>::iterator beg=tok.begin(); beg!=tok.end(); ++beg)
{
cout << *beg <<endl;
}
b) string str = ";!!;miaocl|zhangwh ||-hujian--terry|";
typedef tokenizer<char_separator<char> > tokenizers;
char_separator<char> sep("-;", "|", keep_empty_tokens);
tokenizers tokens(str, sep);
for (tokenizers::iterator tok_iter = tokens.begin(); tok_iter != tokens.end(); ++tok_iter)
{
cout << "<" << *tok_iter << "> ";
}
c) string s = "20090321";
int offsets[] = {4,2,3};
offset_separator f(offsets, offsets+3, true, false);
tokenizer<offset_separator> tok(s,f);
for(tokenizer<offset_separator>::iterator beg=tok.begin();
beg!=tok.end(); ++beg)
{
cout << *beg << endl;
}
2009年3月20日星期五
【原】svn服务器与客户端hooks脚本的使用
——主要谈提交前阻止空信息(pre-commit)和提交后自动发邮件(post-commit)这两个功能
本文用到的所有代码及工具下载:svn-hooks.rar
——包括pre-commit.bat,Post-commit.bat,blat.exe,maillist.txt等。
关于svn几个常用的hooks网上写的不少,相关代码被改的五花八门,很难有可以直接拿来用的(拿来主义总不像想象中的那么顺利...)。我这里只写Windows平台的,也不用python或者perl之类的需要装解释器的脚本,麻烦,只用bat,能达到目的不就行了嘛。
总的来说服务器脚本更实用一些,除了传入参数之外,更多参数可以通过svnlook命令来获得,所以能得到更多的信息来组织邮件内容;而客户端脚本虽说有传入参数比较多,但有些重要参数还是无法获得,所以并不好用。比如提交后自动发邮件的脚本,有些版本库我想实现只有管理员提交才发邮件,而其他人提交则不发邮件的功能。本来我想在管理员所用的客户端上加post-commit脚本,但很无奈版本库和提交文件列表两项参数无法获取(可能有绕弯的方法但我没找到),所以后来就在服务器脚本里加了对提交者的判断,从而达到了过滤的目的,也比较easy。
最终发邮件时调用:blat "%LOG_FILE%" -tf %MAIL_LIST% -f %SENDER% -s "[svn] %REPOS_CP%, rev %REV%, %AUTHOR%" -base64 -charset Gb2312,这是针对发送邮件不需要认证的的命令。如果服务器需要进行用户认证,那么就要加上-u <username> -pw <password>,即用户名和密码。经过我的调研发现,Gmail不能用,因为它需要SSL认证,要用也可以,需要配合stunnel一起使用,太麻烦了;163邮箱需要认证,因此要带上用户名和密码;而创世内部邮箱无需认证,所以最终还是选用了公司邮箱,其他邮箱没有再作调研。最后snv自动发送的邮件截图如下:

其实除了发邮件,还可以根据自己的需要添加其他功能脚本,比如向公司内部即时通信软件发消息等,沟通效率会更高。这就可以任由你来发挥了,呵呵。
svn hooks科普教材:
http://www.worldhello.net/doc/svn_hooks/svn_hooks.mm.htm
本文用到的所有代码及工具下载:svn-hooks.rar
——包括pre-commit.bat,Post-commit.bat,blat.exe,maillist.txt等。
关于svn几个常用的hooks网上写的不少,相关代码被改的五花八门,很难有可以直接拿来用的(拿来主义总不像想象中的那么顺利...)。我这里只写Windows平台的,也不用python或者perl之类的需要装解释器的脚本,麻烦,只用bat,能达到目的不就行了嘛。
总的来说服务器脚本更实用一些,除了传入参数之外,更多参数可以通过svnlook命令来获得,所以能得到更多的信息来组织邮件内容;而客户端脚本虽说有传入参数比较多,但有些重要参数还是无法获得,所以并不好用。比如提交后自动发邮件的脚本,有些版本库我想实现只有管理员提交才发邮件,而其他人提交则不发邮件的功能。本来我想在管理员所用的客户端上加post-commit脚本,但很无奈版本库和提交文件列表两项参数无法获取(可能有绕弯的方法但我没找到),所以后来就在服务器脚本里加了对提交者的判断,从而达到了过滤的目的,也比较easy。
- 提交前阻止空信息(pre-commit.bat)
- 提交后自动发邮件(post-commit.bat)
最终发邮件时调用:blat "%LOG_FILE%" -tf %MAIL_LIST% -f %SENDER% -s "[svn] %REPOS_CP%, rev %REV%, %AUTHOR%" -base64 -charset Gb2312,这是针对发送邮件不需要认证的的命令。如果服务器需要进行用户认证,那么就要加上-u <username> -pw <password>,即用户名和密码。经过我的调研发现,Gmail不能用,因为它需要SSL认证,要用也可以,需要配合stunnel一起使用,太麻烦了;163邮箱需要认证,因此要带上用户名和密码;而创世内部邮箱无需认证,所以最终还是选用了公司邮箱,其他邮箱没有再作调研。最后snv自动发送的邮件截图如下:
其实除了发邮件,还可以根据自己的需要添加其他功能脚本,比如向公司内部即时通信软件发消息等,沟通效率会更高。这就可以任由你来发挥了,呵呵。
svn hooks科普教材:
http://www.worldhello.net/doc/svn_hooks/svn_hooks.mm.htm
2009年3月18日星期三
【原】引玉系列之“启航之旅”实习生计划海报设计心得
创意以及技巧上的东西就不多说了,主要写下整体设计思路及制作过程。
首先由“启航之旅”进行分析创意,设计草图,主要画面构思:海天一线的蓝色画面,蓝天上的白云,水面上的白帆。确定了思路之后着手进行海报制作:
1. 新建文件,确定画面色调,模拟天空水面。








首先由“启航之旅”进行分析创意,设计草图,主要画面构思:海天一线的蓝色画面,蓝天上的白云,水面上的白帆。确定了思路之后着手进行海报制作:
1. 新建文件,确定画面色调,模拟天空水面。


3.这时候,水面的感觉还不够清澈,没有深度感。对其做光照处理,模拟真实水面的光线折射效果。

4.做水面上的白云,找合适的图片用蒙版进行编辑融合,然后用画笔工具进行局部及边缘调整,或者按所需要的形状重新绘制。PS自带的圆头笔刷,注意云彩的走向以及结构即可。

5.增加高空的云彩,根据透视原理及光的漫反射分析,这里的云层应该更加透明一些,饱和度略低于水面上的云。制作方法同上。

6.添加一个光晕效果,丰富画面。


7.在天空和水面之间加入一片绿地,标识地平线。弱化中间的部分,强调透视。


8.按照最初的构思寻找合适的帆船素材,抠图。

9.调节至合适大小,放在画面的预留位置上。


9.调节至合适大小,放在画面的预留位置上。

10.对船和水面进行合成,主要是处理船身的投影,以及驶过划开的波浪。


11.添加画面元素,空中的飞机,水面飞鸟。找合适的素材进行抠图处理。

12.对添加的画面元素进行合成加工,如飞鸟的倒影,飞机划过天空的尾气。
到这一步,整个海报画面已经基本完成。在以上的步骤中不断对画面整体色调进行微调。
到这一步,整个海报画面已经基本完成。在以上的步骤中不断对画面整体色调进行微调。

13.按设计草图添加画面的主题文字内容以及辅助文字部分,完成整个海报的制作。

2009年3月16日星期一
【原】设计3+2之建模相关
浅尝的小结了下建模中常用到的相关命令:

1.Edit Mesh多用于多边形编辑
2.Shapes二维物体编辑
3.Editmesh修改器的相关参数
4.System Unit系统单位
很常用的快捷键:
ctrl+z 返回上一步操作
ctrl+x用专家视图方式显示
ctrl+o打开文件
常用视图:
/p 透视图
t 顶视图
l 左视图
f 前视图/
ctrl+u用户视图
m 材质编辑
f10 快速渲染
f9 查看渲染效果
一个简单的建模效果:

2009年3月15日星期日
【原】ArcGIS中最短路径的实现(一)
最短路径分析属于ArcGIS的网络分析范畴。而ArcGIS的网络分析分为两类,分别是基于几何网络和网络数据集的网络分析。它们都可以实现最短路径功能。下面先介绍基于几何网络的最短路径分析的实现。以后会陆续介绍基于网络数据集的最短路径分析以及这两种方法的区别。
几何网络是一种特殊的特征要素类,由一系列不同类别的点要素和线要素(可以度量并能图形表达)组成的,可在FeatureDataset下面创建,可进行图形与属性的编辑。包括流向分析和追踪分析两大功能。主要接口是ITraceFlowSolver。我们先在一幅地图上做出一个几何网络才能进行最短路径分析。下面是主要的一些步骤(ArcMap帮助中琐碎的说明有三四十项,被我省略很多):
几何网络是一种特殊的特征要素类,由一系列不同类别的点要素和线要素(可以度量并能图形表达)组成的,可在FeatureDataset下面创建,可进行图形与属性的编辑。包括流向分析和追踪分析两大功能。主要接口是ITraceFlowSolver。我们先在一幅地图上做出一个几何网络才能进行最短路径分析。下面是主要的一些步骤(ArcMap帮助中琐碎的说明有三四十项,被我省略很多):
- 打开ArcCatalog,连接到包含地图的文件夹。
- 在空白处,右键新建一个“Personal GeoDatabase”。
- 在生成的Personal GeoDatabase上右键新建一个feature dataset。
- 双击Personal GeoDatabase进去,找到刚才new出的feature dataset,右键Import导入Feature Class(Single),选择要建立几何网络的图层或者shape文件。
- 然后再右键新建一个Geometric Network,选择从已存在的图元中建立几何网络。
- 打开ArcMap,把刚才建立的“Personal GeoDatabase Feature Class”添加到地图中,这样几何网络就建立好了。
这样我们就建立好一个几何网络了。我们现在要通过编程来实现最短路径,用到的接口主要有INetworkCollection,IGeometricNetwork,IPointToEID,ITraceFlowSolverGEN(它实现了ITraceFlowSolver的接口),INetSchema,IEIDHelper等。主要步骤如下:
- 获取几何网络工作空间
- 定义一个边线旗数组,把离点串最近的网络元素添加进数组
- 设置开始和结束边线的权重
- 进行路径分析
- 得到路径分析的结果
具体的程序太过繁琐、冗长了,这里不便贴出,可以打开这个链接查看源程序。http://www.cnblogs.com/3echo/archive/2008/01/24/865527.html
相关链接:ArcGIS中最短路径的实现(二)

【原】Boost库之tuple、any和variant的使用
Boost库中提供了三种比较实用的数据结构,分别是tuple、any和variant。它们的共同优点就是支持类型安全地存储和获取数据。灵活地使用这三种数据结构,对我们进行程序设计无疑是大有裨益的。下面分别加以介绍。
tuple支持一次直接声明和使用n个不同数据类型的变量。对于有多个返回值的函数,我们再也不用定义一个结构体作为函数的返回值类型了,也不用通过对参数进行引用来传出返回值(这样返回值的概念不太明确),而是可以直接使用tuple。
◆ 声明一个tuple类型的对象:tuple<int,double,string> triple(42, 3.14, "hello world");
◆ 获得tuple中某个变量的值:string s = get<2>(triple);
◆ 获得tuple中所有变量的值:tie(nAdd, dbSub, strText) = triple;
◆ 通过几个变量构造一个tuple类型的变量:tuple<int,int> temp = make_tuple(3, 5);
any支持存储任意类型的变量,但它只允许你在知道类型的前提下访问它的值。如果类型不符合,则any会抛出一个bad_any_cast的异常。如果访问的是指针,则类型符合时返回的指针是一个有效值,否则返回的指针为空(此时不会抛出异常)。
◆ 给any赋任意类型的值:any a; a = 42; a= string("hello world"); a=3.14;
◆ 获得any中存储的值:double dbTemp = any_cast<double>(a);
◆ 获得any中存储值的指针:string *pString = any_cast<string *>(a);
variant支持存储和操作来自于多个不同类型的变量。获得variant中当前存储的值时,如果给定的类型与实际存储值的类型不符合,会抛出一个bad_get的异常。如果要获得的是指针,则类型符合时返回的指针是一个有效值,否则返回的指针为空(此时不会抛出异常)。这里需要着重谈一下variant与tuple和any的区别:tuple可以保存n个变量的值,而variant只能保存一个变量的值; any可以保存任意类型的变量,而variant只能保存指定数据类型的变量。
◆ 声明一个variant类型的对象:variant<int,double,string> va("hello world");
◆ 给variant赋值: va=3.14; va=42;
◆ 获得variant中当前存储的值:int nTemp = get<int>(va);
◆ 获得指向variant中存储的值的指针:string *pString = get<string *>(&va);
tuple支持一次直接声明和使用n个不同数据类型的变量。对于有多个返回值的函数,我们再也不用定义一个结构体作为函数的返回值类型了,也不用通过对参数进行引用来传出返回值(这样返回值的概念不太明确),而是可以直接使用tuple。
◆ 声明一个tuple类型的对象:tuple<int,double,string> triple(42, 3.14, "hello world");
◆ 获得tuple中某个变量的值:string s = get<2>(triple);
◆ 获得tuple中所有变量的值:tie(nAdd, dbSub, strText) = triple;
◆ 通过几个变量构造一个tuple类型的变量:tuple<int,int> temp = make_tuple(3, 5);
any支持存储任意类型的变量,但它只允许你在知道类型的前提下访问它的值。如果类型不符合,则any会抛出一个bad_any_cast的异常。如果访问的是指针,则类型符合时返回的指针是一个有效值,否则返回的指针为空(此时不会抛出异常)。
◆ 给any赋任意类型的值:any a; a = 42; a= string("hello world"); a=3.14;
◆ 获得any中存储的值:double dbTemp = any_cast<double>(a);
◆ 获得any中存储值的指针:string *pString = any_cast<string *>(a);
variant支持存储和操作来自于多个不同类型的变量。获得variant中当前存储的值时,如果给定的类型与实际存储值的类型不符合,会抛出一个bad_get的异常。如果要获得的是指针,则类型符合时返回的指针是一个有效值,否则返回的指针为空(此时不会抛出异常)。这里需要着重谈一下variant与tuple和any的区别:tuple可以保存n个变量的值,而variant只能保存一个变量的值; any可以保存任意类型的变量,而variant只能保存指定数据类型的变量。
◆ 声明一个variant类型的对象:variant<int,double,string> va("hello world");
◆ 给variant赋值: va=3.14; va=42;
◆ 获得variant中当前存储的值:int nTemp = get<int>(va);
◆ 获得指向variant中存储的值的指针:string *pString = get<string *>(&va);
2009年3月9日星期一







【原】设计3+2
平面设计更多更多传统的归属与2D的范畴,的确,2D可以更精致细腻的表达图像,把一些细节完美地表现出来,但是,现在有越来越多的平面设计师把自己的设计与3D结合了起来,也就出现了越来越多的精致美观的有着更强的视觉冲击力的作品!
比如网站方面,基本上图片加文字,好一些的加入了FLASH动效果,而现在高档的网站则更多的结合了3D效果,可以让人真实的更加身临其境的,全方位体会它的产品和想表达的境界!最近一直在接触宣传册的设计,下面聊些关于用3D做宣传册效果的尝试,以前做印刷品的效果图,我通常还 是会用平面工具,这样也可以很好表达出想要展示的效果,但如果上,下,左,右效果都要的话,我就要出N张不同的图(同时还要注意透视关系),那叫一个烦琐,,如果利用3D对作品进行表现就可以大大加快制作速度,同时在不失创意的情下,可以更有效地把握自己要表达的意图。

同时3D制作过程中的:
1.视点(摄像机)是可以任意移动并改变角度
2.灯光(光影的变化)光源位置明暗效果
3.质感(材质渲染)
都显得非常灵活,不但能细致地表现对象,更能更易于修改画面!
本人还处在学习摸索阶段,希望以后能有更好的想法与各位分享!
:D以下是2张简单的建模贴图的应用:

比如网站方面,基本上图片加文字,好一些的加入了FLASH动效果,而现在高档的网站则更多的结合了3D效果,可以让人真实的更加身临其境的,全方位体会它的产品和想表达的境界!最近一直在接触宣传册的设计,下面聊些关于用3D做宣传册效果的尝试,以前做印刷品的效果图,我通常还 是会用平面工具,这样也可以很好表达出想要展示的效果,但如果上,下,左,右效果都要的话,我就要出N张不同的图(同时还要注意透视关系),那叫一个烦琐,,如果利用3D对作品进行表现就可以大大加快制作速度,同时在不失创意的情下,可以更有效地把握自己要表达的意图。
同时3D制作过程中的:
1.视点(摄像机)是可以任意移动并改变角度
2.灯光(光影的变化)光源位置明暗效果
3.质感(材质渲染)
都显得非常灵活,不但能细致地表现对象,更能更易于修改画面!
本人还处在学习摸索阶段,希望以后能有更好的想法与各位分享!
:D以下是2张简单的建模贴图的应用:
【原】关于const修饰符的问题
对const修饰符的使用一直感觉疙疙瘩瘩的,因为用的不是很多。上周写了个小程序,搞清楚了它的用法。话不多说,先贴程序。
- const int n = 10;
- const char * pszTemp = "a";
- char const * pszTemp2 = "c";
- char * const pszTemp3 = "b";
- const char * const pszTemp4 = "e";
- pszTemp = "d";
- pszTemp2 = "e";
- pszTemp3 = "f";
- pszTemp4 = "f";
- lstrcpy(pszTemp, "d");
- lstrcpy(pszTemp2, "d");
- lstrcpy(pszTemp3, "d");
- lstrcpy(pszTemp4, "f");
把这段程序拿到VC6的环境下编译,会发现编译出错。第8、9、10、11和13行都有错误。我们先从第2行开始分析。第2行定义了一个名叫pszTemp 的字符串指针,const放在char *之前,表明它是一个指向常量的指针变量,它指向的常量值不可以改变,所以第10行会编译出错,但是它保存的地址却可以改变,所以我们仍然可以通过改变它指向的地址来改变它的值。第3行同第2行。第4行定义了一个常指针,表明它本身是常量,而不是它指向的对象声明为常量。所以第8行出错,而第12行却可以通过。第5行是定义了一个指向常量的常指针,所以无论是对它指向的值的改变还是指针本身值的改变都是不允许的。因此,第9行和13行写法都是错误的。
下面再贴几行代码,有兴趣的读者可以指出其中出错的行数。
- const int *pAge = new int(1);
- int const *pAge2 = new int(2);
- int * const pAge3 = new int(3);
- const int * const pAge4 = new int(4);
- *pAge = n;
- *pAge2 = n;
- *pAge3 = n;
- *pAge4 = n;
- pAge = &n;
- pAge2 = &n;
- pAge3 = &n;
- pAge4 = &n;
【原】Boost库使用入门
Boost库是一套开放源代码、高度可移植的C++准标准库。它相当于STL库的延续和扩充,其设计理念和STL比较接近,都是利用泛型让复用达到最大化。
Boost库当前的最新版本为V1.38.0,大家可以到Boost库的官网http://www.boost.org/去下载,下载后直接安装即可。这里需要格外注意的是,Boost的绝大部分库只需要包含头文件就可以直接使用了,而另外一些库,比如正则表达式库(regex)、线程库(thread),需要编译生成lib和dll后才能使用。
Boost库主要包含以下几个大类:
1.字符串及文本处理
2.输入/输出
3.数学和数字处理
4.泛型编程和模板元编程
5.函数对象及高级编程
6.数据结构、容器、迭代器和算法
7.杂项
大家在学习Boost库的过程中,肯定会遇到这样或那样的问题,这是很正常的。这里,我把自己在学习中总结出来的一些注意事项列出来,以供大家参考:
1.由于VC6对模板类的支持不是很好,因此,使用有些Boost库(如string_algo库)时在VC6下无法编译成功,可以使用VC7或更高的VC版本来解决这一问题。
2.由于VC6的编译器并不是完全支持C++标准,因此使用有些库时即使编译通过了,但运行的结果可能会不正确,解决方法同上。
3.安装完Boost库之后,需要将Boost库的根路径添加到VC的Include Files和Library Files中。
4.与使用STL库一样,使用Boost库时,最好使用using namespace boost来声明名字空间boost。
最后,列出学习Boost库的一些实用资源:
1.Boost库的SDK
2.《超越c++标准库——boost程序库导论》
3.Boost官方网站
4.Boost中文站
OK,Boost库的概述就讲这么多。让我们赶快进入Boost库的神秘世界吧,Let′s go!
Boost库当前的最新版本为V1.38.0,大家可以到Boost库的官网http://www.boost.org/去下载,下载后直接安装即可。这里需要格外注意的是,Boost的绝大部分库只需要包含头文件就可以直接使用了,而另外一些库,比如正则表达式库(regex)、线程库(thread),需要编译生成lib和dll后才能使用。
Boost库主要包含以下几个大类:
1.字符串及文本处理
2.输入/输出
3.数学和数字处理
4.泛型编程和模板元编程
5.函数对象及高级编程
6.数据结构、容器、迭代器和算法
7.杂项
大家在学习Boost库的过程中,肯定会遇到这样或那样的问题,这是很正常的。这里,我把自己在学习中总结出来的一些注意事项列出来,以供大家参考:
1.由于VC6对模板类的支持不是很好,因此,使用有些Boost库(如string_algo库)时在VC6下无法编译成功,可以使用VC7或更高的VC版本来解决这一问题。
2.由于VC6的编译器并不是完全支持C++标准,因此使用有些库时即使编译通过了,但运行的结果可能会不正确,解决方法同上。
3.安装完Boost库之后,需要将Boost库的根路径添加到VC的Include Files和Library Files中。
4.与使用STL库一样,使用Boost库时,最好使用using namespace boost来声明名字空间boost。
最后,列出学习Boost库的一些实用资源:
1.Boost库的SDK
2.《超越c++标准库——boost程序库导论》
3.Boost官方网站
4.Boost中文站
OK,Boost库的概述就讲这么多。让我们赶快进入Boost库的神秘世界吧,Let′s go!
2009年3月8日星期日
【原】AE之鹰眼的实现
大家都用过百度地图或者googole地图吧,在它们主地图的右下角,有个小地图窗口,这就是鹰眼窗口。用鼠标拖动鹰眼里的小窗口,则主地图便移动到相应的位置。下面就介绍鹰眼的实现。
鹰眼和主地图的互动,主要体现在两个方面:一是主地图的地图改变了,则鹰眼里的矩形框要移动到对应的位置,以指示当前地图在整个地图中的位置;二是鹰眼的矩形框移动了,则主地图中显示的地图要移动到相应的位置。
AE中显示地图的控件叫 ESRI MapControl,这里主要用到了它的OnAfterDraw事件。在主地图的OnAfterDraw事件中,根据当前地图的大小,改变鹰眼中矩形框的大小;在鹰眼的OnAfterDraw事件中,根据矩形框的位置,确定主地图中地图的位置。google地图的鹰眼还实现了矩形框的拖动,这个也很好实现,呵呵。在鼠标点击到鹰眼控件时,先判断是否在矩形框内,如果在的话,用一个状态量记住这个状态,此时如果鼠标移动,则矩形框跟着相应的移动;若不在矩形框内,则矩形框移动到鼠标点击的位置。
鹰眼和主地图的互动,主要体现在两个方面:一是主地图的地图改变了,则鹰眼里的矩形框要移动到对应的位置,以指示当前地图在整个地图中的位置;二是鹰眼的矩形框移动了,则主地图中显示的地图要移动到相应的位置。
AE中显示地图的控件叫 ESRI MapControl,这里主要用到了它的OnAfterDraw事件。在主地图的OnAfterDraw事件中,根据当前地图的大小,改变鹰眼中矩形框的大小;在鹰眼的OnAfterDraw事件中,根据矩形框的位置,确定主地图中地图的位置。google地图的鹰眼还实现了矩形框的拖动,这个也很好实现,呵呵。在鼠标点击到鹰眼控件时,先判断是否在矩形框内,如果在的话,用一个状态量记住这个状态,此时如果鼠标移动,则矩形框跟着相应的移动;若不在矩形框内,则矩形框移动到鼠标点击的位置。
【原】谈谈网络视频监控系统软件平台的发展趋势
从当前行业的局面来看,伴随着各厂商硬件产品差距的日益缩小,视频监控在未来的竞争将是软件平台的竞争。谁家平台做的好,谁就在竞争中占有绝对优势。那么,软件平台会如何发展,向着哪个方向发展?个人看来有以下几方面趋势:
- 需要具备支持其他厂商设备接入的能力,我们称之为“吸收性”。做大系统,做运营,不能方便的接入其他厂商的设备怎么可以?吸收性强,系统才有可能做大。所以,系统在设计之初就要考虑这一点。
- 系统要有足够的扩容能力。当系统中的设备由原有的几十台突然上升为几百台甚至上千台的时候,如何才能够微笑着去面对?假设系统设计之初便考虑到这点,那么一个灵活而有效的系统结构将会使该问题迎刃而解。
- 必须具备一套功能全面、界面友好并且易于定制的客户端软件。以前我们说服务器的性能好坏很重要,但是将来客户端的性能会需要我们更多的投入,良好的用户体验不仅仅能够锦上添花,有时甚至可以起到决定性的关键作用。
- 系统要便于搭建和配置、易组网。在系统模块较多的情况下,这个问题需要尤为注意。
- 具备良好的平台兼容性,这可能已经是默认的潜规则了,不需要多说,Linux必须要支持。
- 具备良好的稳定性,这点真是易说不易做。监控这个行业要求我们服务器稳定,客户端也要稳定。做一个系统很简单,想做好就要下功夫。
目前应该还没有一个厂家敢说他的系统已经做到最好,事实上很多厂家还没有自己的系统。这让我们的竞争变得更加残酷,也让我们对未来充满信心。因为创世已经走在了前面,我们还将继续大踏步向前迈进。
2009年3月5日星期四
2009年3月4日星期三
订阅:
评论 (Atom)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}